![[CLS Framework]](images/clshead.gif)
![]()
|
TTT
Homepage
CLS Framework Introduction Section map Overview Applications: ·Representation ·Design ·Sharing ISO 12620 data categories Downloads XML information Copyright © 2000 Translation Research Group Send comments to comments@ttt.org Last updated: January 27, 2001 |
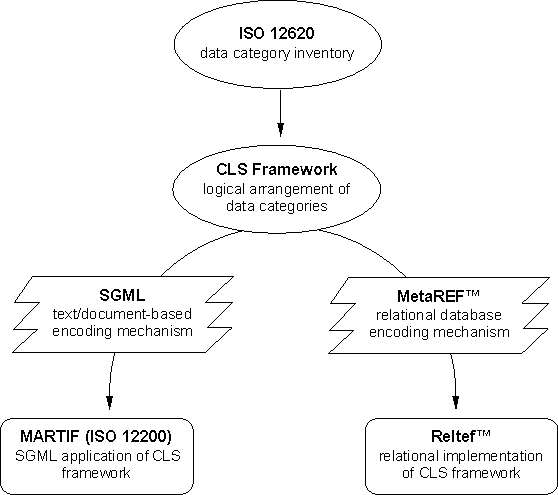
Daniel Hardman, CMR-TermSoftRevised 1999-03-18 Reltef™ and MetaRef™ © 1996-2000 Background assumptionsThis document builds on the termbase data model framework outlined in a separate document entitled "The CLS Framework". The CLS Framework is a logical organization of ISO 12620 data categories that reflects certain tenets of terminology theory and conceptualizes terminology data models using building blocks familiar to professional terminologists.
In order to arrive at a final data model for a termbase, we assume the CLS Framework as a point of departure. The data categories and the categorical hierarchy proposed in the CLS Framework can be implemented in various ways. Two possible encoding paradigms are SGML and relational database systems. When the CLS Framework is implemented with SGML, the result is MARTIF (ISO 12200). When the CLS Framework is implemented in relational database systems using MetaREF™ (outlined below), the result is Reltef™. Because MARTIF and Reltef™ share a common framework, they are completely compatible and congruent. Reltef™ is a specific application of MetaREF™, an abstract data model designed by CMR-TermSoft. The MetaREF™ model consists of an E-R diagram and a set of tables and relationships that can be implemented in any mid-range (e.g., MS Access) to high-range RDBMS (e.g., Oracle, SQL Server, Ingres, Informix, Sybase, etc.). The Reltef™ model consists of the abstract structure of MetaREF™ plus tuples in several MetaREF™ "meta" tables. This data locks the DBMS into the specific terminology model an application requires. A Reltef™ implementation consists of the Reltef™ model plus a coherent body of terminological data stored in non-meta tables. Reltef™ takes advantage of many strengths of a traditional DBMS, including integrity constraints, data normalization, access to data through traditional and extended SQL, business rules, and so forth. It also provides enormous flexibility and can be customized to address the needs of many data sets in a wide variety of human languages. Basic PhilosophyRelational systems do certain things very well when it comes to data storage, manipulation, and retrieval. They share a fairly standardized query language (SQL); they are able to impose many constraints to ensure the validity of data; they typically import and export data to other RDBMS engines with a high degree of transparency (assuming congruent data models); they support multiple concurrent access, record locking, etc. However, RDBMSs also have certain weaknesses when it comes to highly linguistic data. They typically index information using a single collating sequence that must be applied to the database as a whole; they have no standardized way of encoding multiple languages (especially if the CJK languages are part of the mix); many validation routines for text fields are English-oriented; their query interface has no built-in linguistic savvy. Also, various relational implementations of terminological data models are highly incompatible with one another because of fundamentally different assumptions about what the atomic units of data and structure in the database should be. SGML can be considered more properly a document encoding language as opposed to a database system. It allows for detailed "templates" (DTDs) that specify a particular structure; these templates can be populated by an infinite (but bounded) variety of specific instantiations. A well-known SGML DTD is HTML, the language used to encode documents on the Web. Like RDBMSs, SGML has both strengths and weaknesses. Its strengths include true platform independence, extremely flexible handling of multiple languages, automated processing and conversion by SGML-aware software, structural and data integrity constraints, and conformity validation. Its weaknesses include the lack of a query language, no indexing capability, an inability to regulate and distribute access to data, and lack of SGML management engines that provide database-like functionality. Reltef™ stands for "Relational terminology encoding format", and represents a fusion of these two normally distinct approaches. Reltef™ data is stored in relational tables and joined by standard relationships; it can be queried using SQL, described by an E-R diagram, and edited using RDBMS tools. However, it also parallels the structure of an SGML document and borrows from SGML to deal with character encoding, collating sequences, and other multilingual issues. It can be converted automatically between an SGML document and relational tables to allow information to flow across platform, language, and software boundaries with maximum ease and minimum data loss. Molecular and atomic views of dataChemists make important generalizations about matter on at least two very different levels: molecular and atomic. Certain molecules may have common characteristics even though their specific structures are somewhat different (acid~base, organic~inorganic, strand~ring~crystal, etc.) It is valid and useful to think about matter from a molecular perspective. However, an atomic-level classification is also necessary to explain many phenomena, such as why particular molecules form and how they can combine. Reltef™ views terminological data at two different levels of abstraction. At one level the major objects under consideration are data category instances--pieces of information that can be classified using the CLS Framework, such as concepts, terms, definitions, and the like. At a more elemental level, Reltef™ recognizes the root entities of MetaREF™: languages, picklists, text values, dates, and so forth. These two perspectives could be called "molecular" and "atomic", respectively. To illustrate these perspectives, consider the following piece of fictional terminological data:
What pieces of data are present in this sample? A terminologist might identify the following data category instances: three terms (one preferred, the other two synonyms), a part of speech, an indication of the grammatical number of a term, a domain, a definition, a context, and two bibliographical references. This valid and relatively intuitive way of conceptualizing the data (in which the primary unit of data is the data category instance) can be thought of as "molecular", in the sense that the data units can be further reduced or generalized. Terms, definitions, contexts and the like share certain common features, regardless of their specific type: they each modify a single parent element; they each have a single value; they each fall into a single data category. A particular configuration of these more elemental building blocks [atoms] yields a data category instance [molecule]. Molecular perspectives are important both to MARTIF and to relational terminology applications. Molecular approachesBecause of its origins in SGML, MARTIF is able to address information
at an atomic level. For convenience, however, most discussions of MARTIF
focus on the molecular perspective, working directly with data categories
familiar to a terminologist. Thus the major building block of a MARTIF
file is a Typical relational terminology models are also molecule-oriented. Concepts, terms, definitions, contexts, bibliographic references, and grammatical information are each conceived of as separate entities, with predefined relationships between the entities encoded as part of the data model: CONCEPT is labeled by one or more TERMs; TERM is demonstrated by one or more CONTEXTs; CONCEPT is identified by one or more DEFINITIONs, etc. In such systems, the concept is usually privileged against all other entities, in the sense that the concept forms a nucleus around which other pieces of information must cluster. Each entity usually corresponds to a separate table, with fields that reflect its particular data characteristics. For example, the term table might have a numeric ID, a 120-character text field to hold the value of the term, and a small field to identify the term's language. It could also have a status field to classify the term as preferred or deprecated, a part of speech field, a grammatical number field, and so forth. Molecular-only models of terminology data have the advantage of being relatively intuitive to a terminologist. However, they also have certain drawbacks. They are typically built in such a way as to preclude the sharing of information with incompatible models. For example, if a relational model requires that all terms have an associated status, and if terminology from an external system has no status on the terms, then the integrity constraints of the DBMS will make it impossible to import the external data. This is a good thing in terms of internal consistency, but may make it difficult to share information. Once a molecular model has been implemented, it also adopts all of the linguistic idiosyncrasies of its RDBMS. For example, Japanese information in an Oracle database may be reliably and safely encoded on a particular flavor of UNIX, but may not transfer at all if that database must be moved to a different machine running a different OS. It almost certainly will not transfer if Oracle is laid aside in favor of another RDBMS somewhere in the future. Some database engines use Unicode internally, but few export it and even fewer allow Unicode-aware queries. If they do allow Unicode queries, there is still the issue of conversion between the OS code page and Unicode during keyboard input, web access, and so forth; any solutions are virtually guaranteed to be implementation-specific and non-transferable. And the RDBMS will probably not sort CJK languages properly. If it does, then it is likely to impose a CJK sort order throughout the database (or possibly allow CJK plus one other order). A Dual PerspectiveReltef™ is innovative in that it conceives of terminological data at both the atomic and molecular levels of abstraction. It uses the MetaREF™ data model to coordinate data at the atomic level, and gains from MetaREF™ all the inherent power of an RDBMS to manage entities, relationships, and integrity constraints. And it allows a query-driven management of the more familiar molecular-level constructs as well. How it worksThe atomic level in Reltef™ is implemented directly through the MetaREF™ data model. The core of this data model is a set of thirteen entities [atoms]:
The first six items above are "meta" entities; they are created (and their corresponding tables filled with information) before any terminological data is added to the database. It is from these meta entities that "MetaREF" (Meta Relational Encoding Format) gets its name. MetaREF™ defines a very abstract layer of informational possibilities. By populating the six meta entities (plus one meta relationship), the specific data model used by an application (in this case, a termbase) is outlined and enforced. In other words, the meta tables together define the structure that constrains and unifies the terminological data at a molecular level. They might be considered catalyst atoms, necessary to the combination of the other atoms in molecular reactions. The remaining seven MetaREF™ entities are populated directly through traditional data entry or import and (in Reltef™) hold the actual terminology data visible to an end user of the system. The information these entities contain may be validated at a molecular level using standard SQL queries. Most information-retrieval queries formulated by end users of the DBMS focus almost entirely on information contained by these entities.
Sample databaseTo illustrate how these entities are actually implemented in the tables of a Reltef™ database, we will create a small sample. We begin by encoding the CLS Framework in the seven meta tables inherited from MetaREF™. This process identifies all the data categories that the Reltef™ database will recognize, how instances of the categories may combine and be indexed, what values are valid for a given data category, and so forth. Once we have completed the meta table population, our database will be specifically terminology-oriented, and will be ready for the input of data recognizable to the termbase end user. The first step is identifying the languages the database will support. This fills the langs table and implements the lang entity. Note that the collating sequence is important for certain kinds of linguistic processing, but is left blank to simplify our example for now.
We must also explain what charset "ISO 8879-1" is. This fills the charsets table and implements the charset entity.
Next we should define some data categories. All Reltef™ databases populate the data categories table (and implement the data categories entity) from the CLS Framework (and via CTI, from ISO 12620). Of course, a particular implementation of Reltef™ need not use all or even most of the myriad data categories outlined there-we only define those kinds of data we are interested in. But we must draw our definition from the standard to ensure compatibility and convertibility. Here it is vital to note that from an atomic perspective, all data categories are created equal. A basic assumption of most relational terminology databases is the centrality of the concept entity, to which terms, definitions and so forth are subservient. There is no intrinsic quality of the MetaREF™ data model that parallels this assumption. In the data categories table, a concept is just another tuple. It is possible to enforce the concept's core quality in Reltef™, but the enforcing occurs in the valid families table (discussed below), not here. The structure of the data categories table is relatively straightforward. The value of each categoryID (and GI name + type) derive directly from ISO 12620. Possible values of the "value type" field are: container (element is a shell that contains other elements), none (element has no value at all), text (free-form language-specific information), code (free-form language-independent information), number, date, and picklist. The "forms link" field tells whether this data category is required to point to another element (as in cross references).
Now we need to give these data categories (each identified by a somewhat cryptic categoryID) a meaningful, language-specific name. This fills the data category names table and implements the data category name entity.
Having given a name to each data category, we need to create picklists for those data categories that require them. This fills the picklists table and implements the picklist entity.
Now we identify a data category index type for all data categories that can be indexed (value-less data categories cannot be indexed). This fills the data category index types table and implements the data category index type entity. Note that in field "index type", the allowed values are: "none" (the data category is not indexed), "whole" (the entire value of each instance of the data category is indexed as a single value, "chunk" (the value of each instance of the data category is divided into chunks and indexed on a per-chunk basis, and "both" (whole + chunk).
Our last task with the "meta" entities is to specify how data categories may combine. This fills the valid families table and implements the relationship data category A may be parent of B (see E-R diagram below). Note that in field "child occurrence rule", the allowed values are: 1 (child must occur exactly once), ? (child must occur 0 or 1 times), * (child must occur 0 or more times), and + (child must occur 1 or more times). The data we place in this table will be used to enforce so-called "business rules" as well as certain kinds of data constraints. For example, by specifying that all concepts (data category 0.3) must have at least 1 child term (data category 1.1.1), we impose a portion of the concept centrality feature mentioned earlier. If a concept is added, then the valid families table will require that at least one term be added as well. We can check for conformance to this information with a simple query. Many DBMS engines allow this kind of query as a validity check whenever a record is added, making molecular-level integrity constraints straightforward and bulletproof.
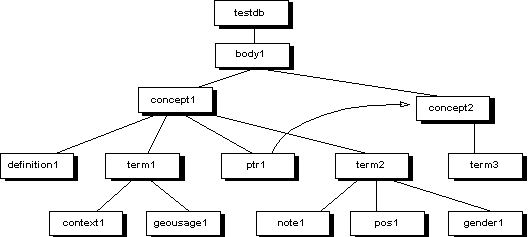
Once these seven tables contain data, we have a sufficient framework to began actually entering terminology data. Let's create a two concepts, three terms, and some simple supporting information, using the following structure:
Here we have uniquely labeled each piece of information using a somewhat arbitrary ID ("term1", "concept2", etc.) Reltef™ imposes some restrictions on these IDs. They are strings of at most 32 chars. They must begin with an alpha, and can contain alphas, digits, hyphens, and periods ("."). But they need not reflect their associated data category. The terminologist who manages a Reltef™ database decides if the IDs should follow a particular convention, or the IDs could be generated automatically during data entry or import. In this case, we have chosen a reasonable convention that seems easy to follow. We begin by adding each data category instance to our elements table:
By adding these tuples to the elements table, we have created instances of various terminological (molecular) data categories. However, at a molecular level some of these newly-created objects are incomplete. For example, the terms, the definition, the context, the note, and the geographical usage note all have text values. In Reltef™'s atomic perspective, the text values are separate entities associated through the element has text value relationship by a common ID. Thus we add the following information to the text values table:
Each element may also have an explicitly associated lang in the elements use lang table (if the element's data category is defined to take a lang attribute):
The gender and part of speech data category instances both draw their value from picklists. Consulting the earlier information we entered in the picklists table, we choose a valid value for each data category instance and enter it in the picklist values table:
Now we can implement the link created by ptr1. We do this in the links table:
Our final step is to index the values of various elements, according to the instructions in the data category index types table. Indexed values are stored in the index values table.
At this point all of our data has been entered. Several Reltef™ tables have not been used (date values, code values, number values). This is because our tiny sample has no data category instances that have date, code, or number values. The structure of these tables and the method of data entry is relatively similar to that of the text values table. Molecular-level interfaceOnce the tables and relationships have been created in a Reltef™ database, the DBMS will automatically maintain what we have called the "atomic" or MetaREF™ level components-the most abstract layer of entities and relationships. For example, the database engine will prevent a text value from being associated with a non-existent language; it will only allow elements to be assigned to valid data categories; it will force picklist values to come from pre-defined picklists; when a particular element is deleted, its associated value, index value, and so forth will also be deleted. This provides one important layer of validation. However, the atomic level is highly abstract, and does not parallel the typical needs of an end user who knows about terms and definitions but not elements and data categories. The typical end user will need to answer queries such as "find all French software engineering terms that are only appropriate in Canada" or "list Spanish equivalents for English terms containing with 'polymorphic'". And the database needs to perform validation at the molecular level as well, to implement rules like "all English terms must have a contextual example" or "each definition must have a bibliographic reference". Both of these kinds of operations are possible running SQL queries against the Reltef™ database:
Of course, many more queries could be written. The queries make molecular-level constructs accessible to the end-user, and also provide a mechanism for molecular-level validation of the database.
Correspondence between tables and entities/relationships
| Applications: Representation; Design; Sharing | | ISO 12620 Data Categories | Downloads | XML info | |